🚀 Product Update New Features & Improvements
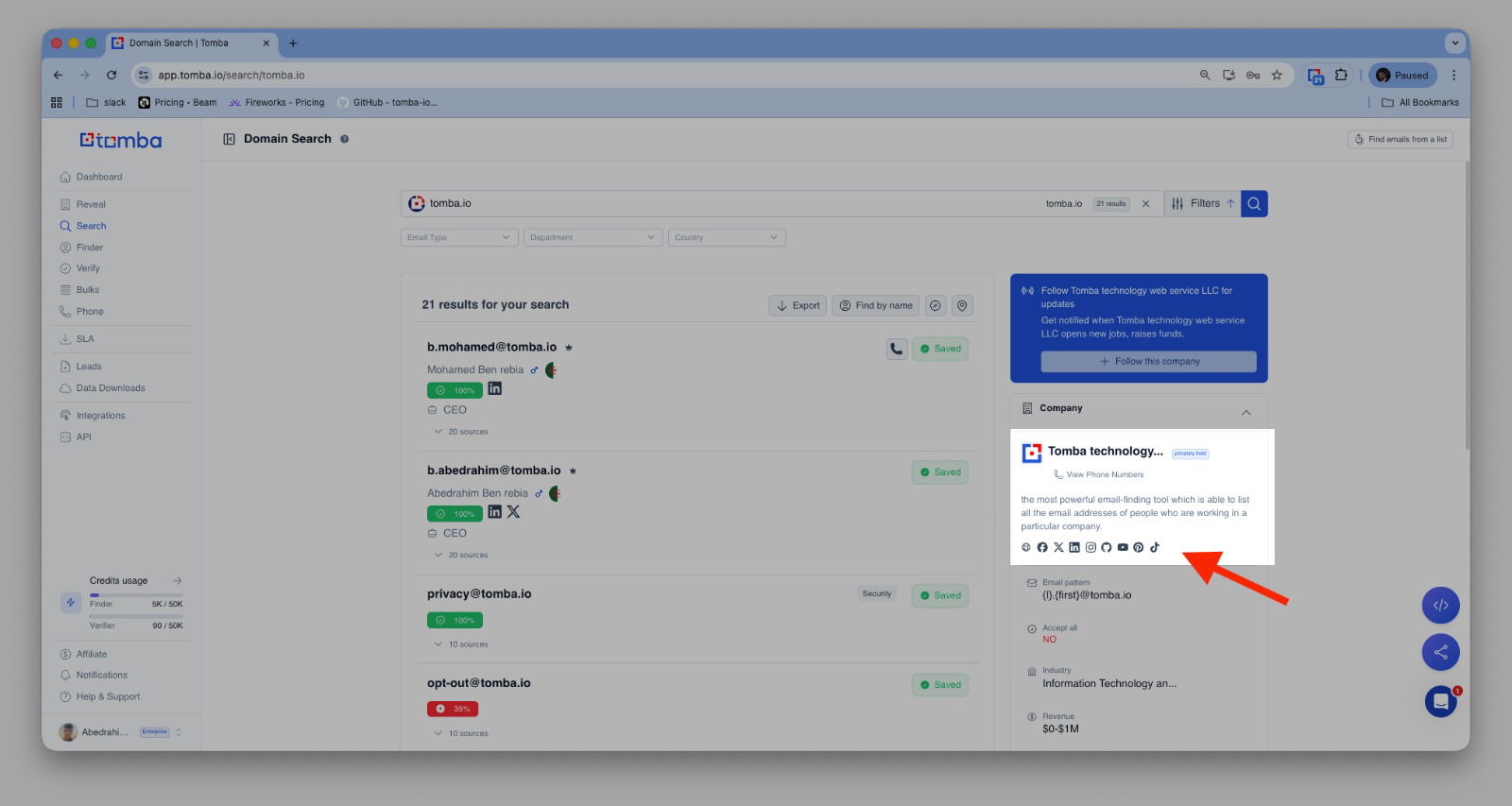
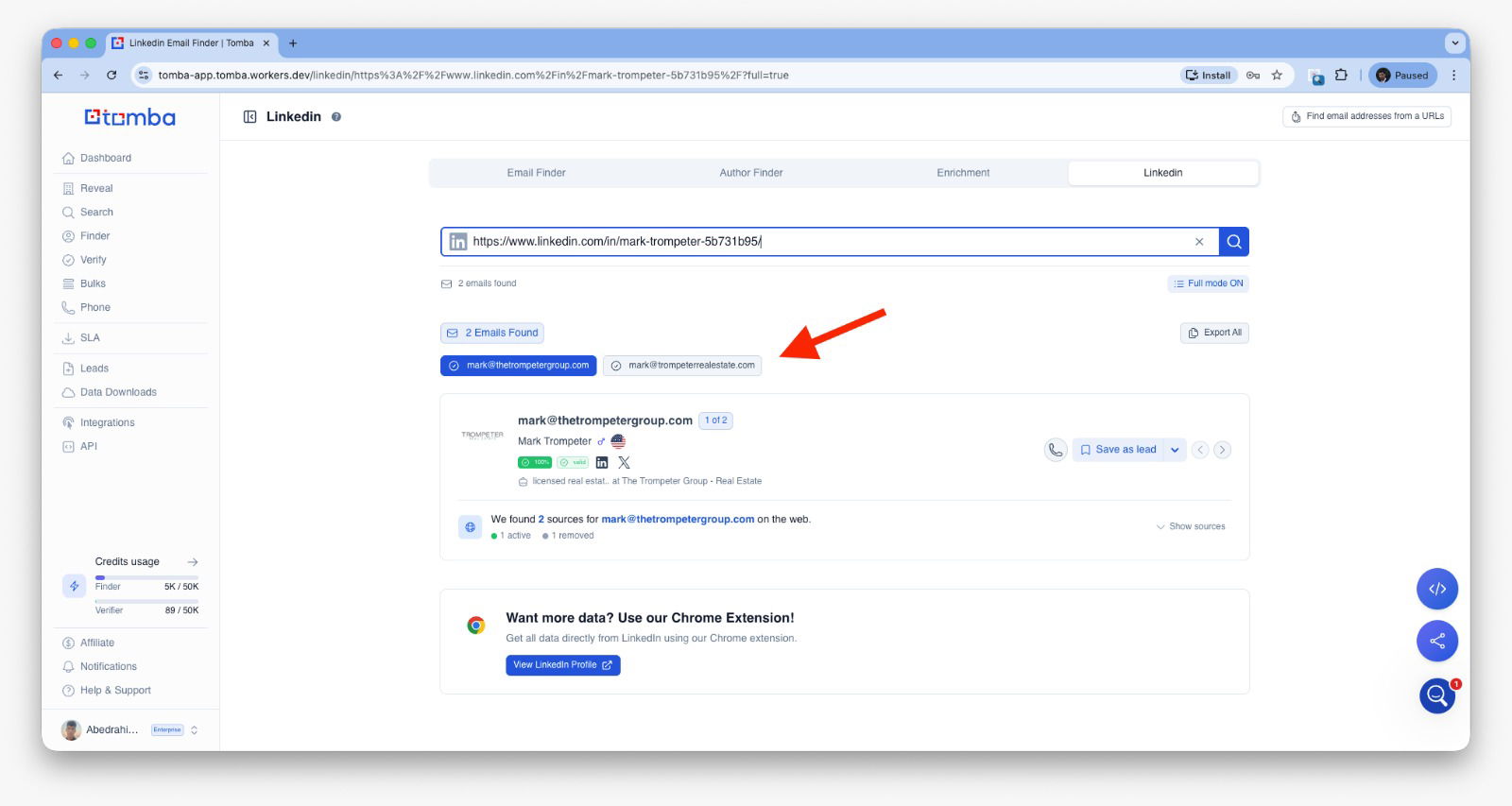
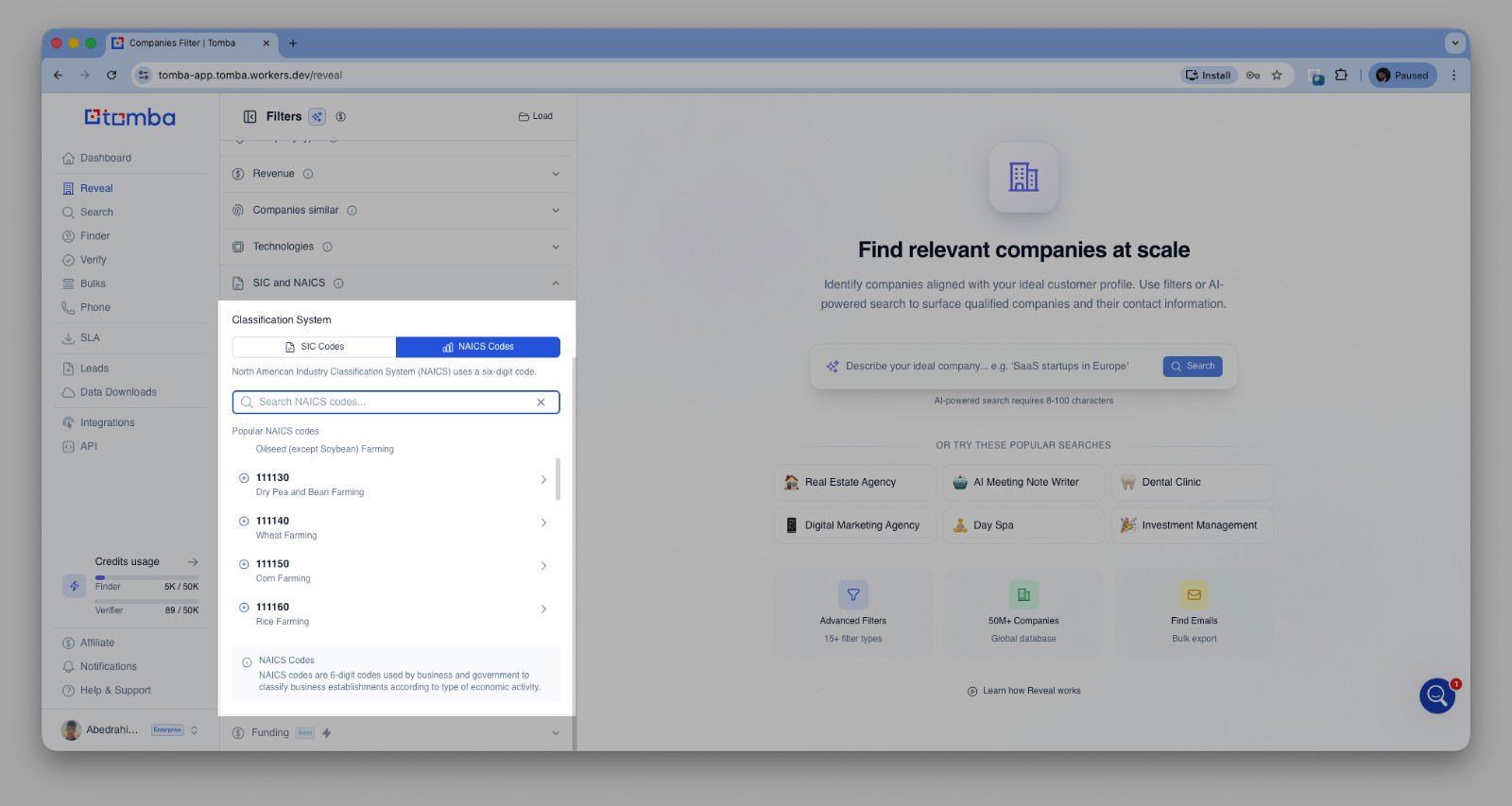
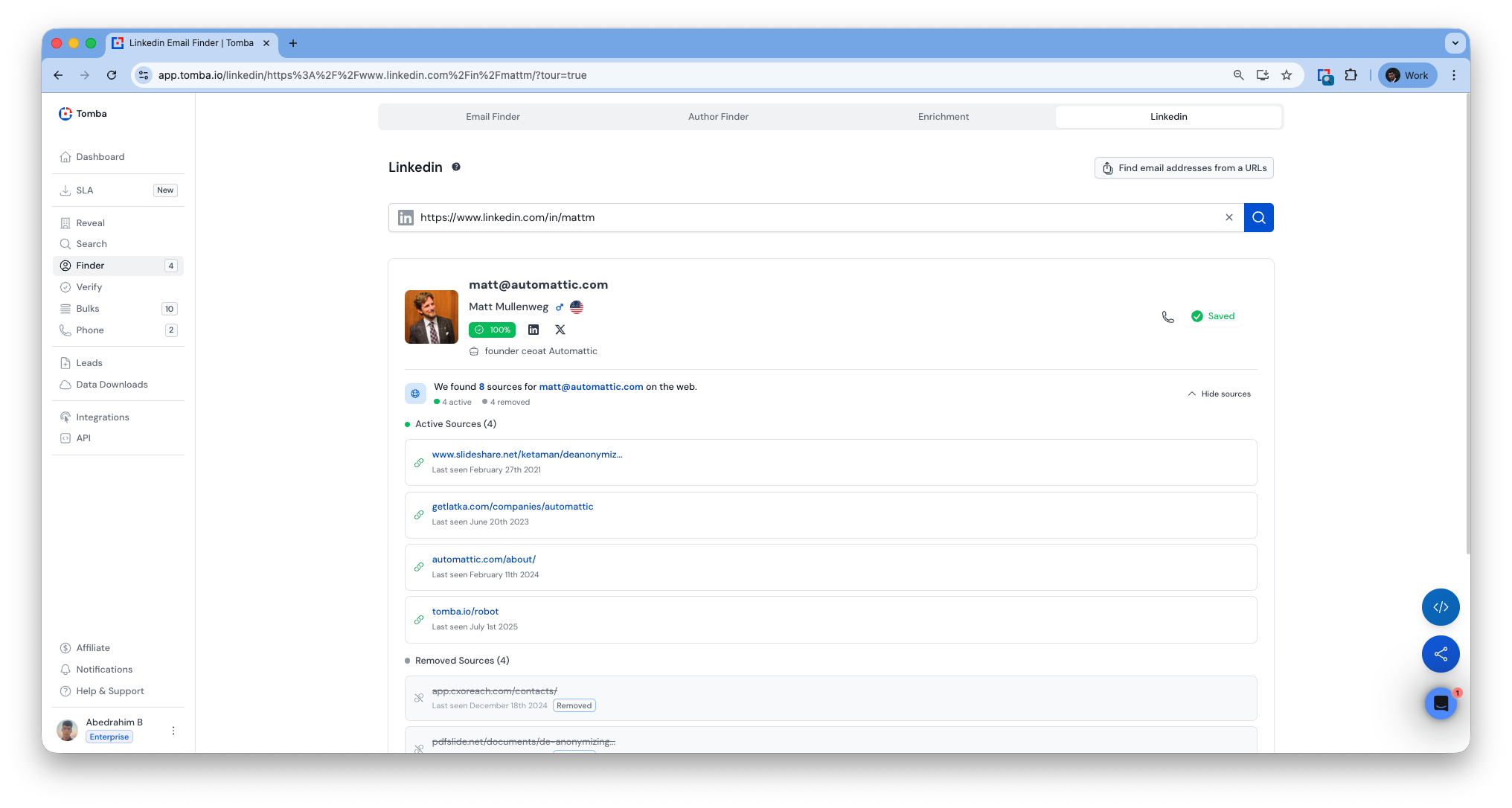
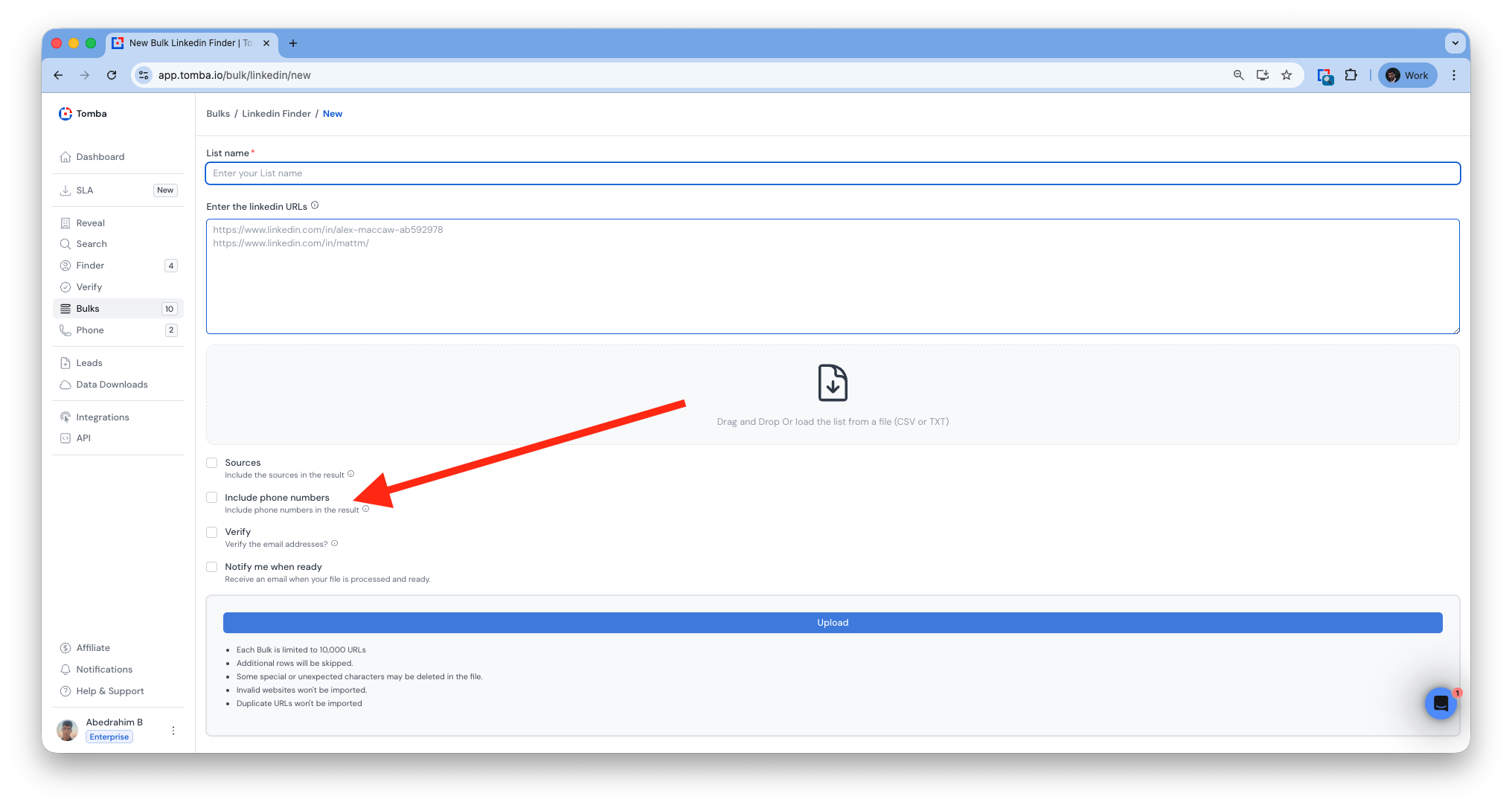
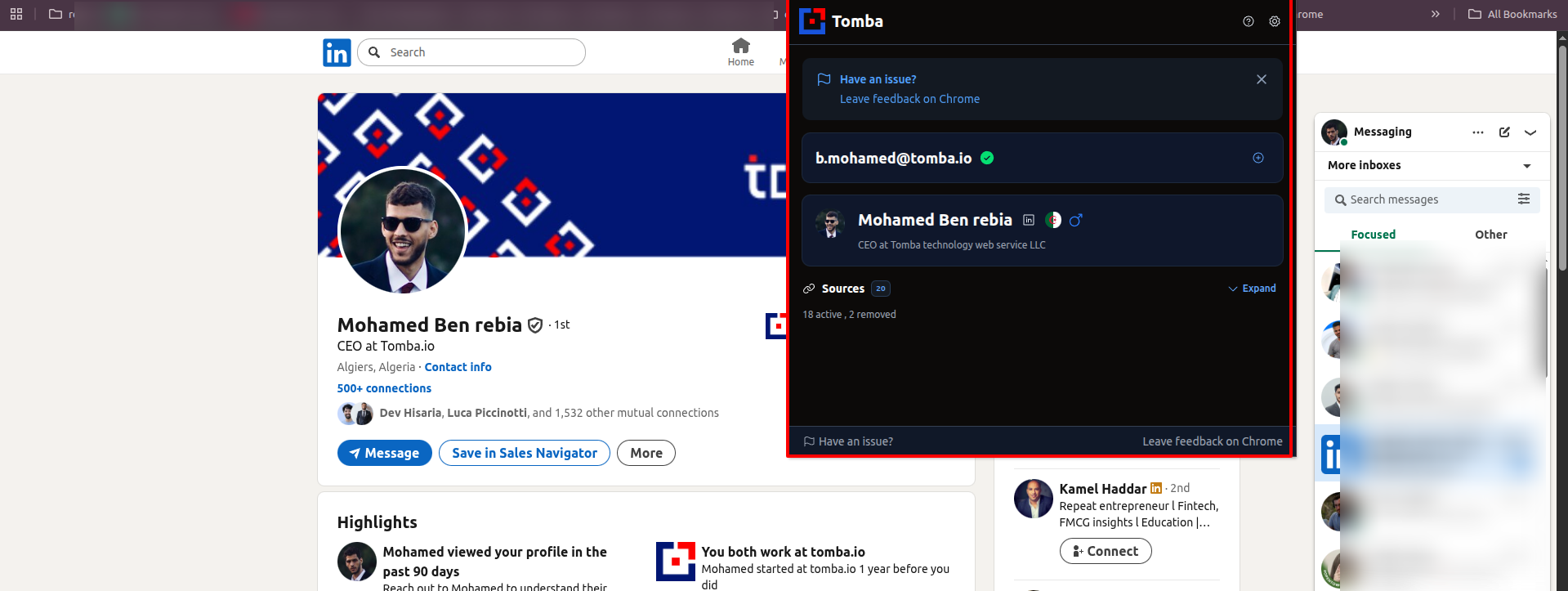
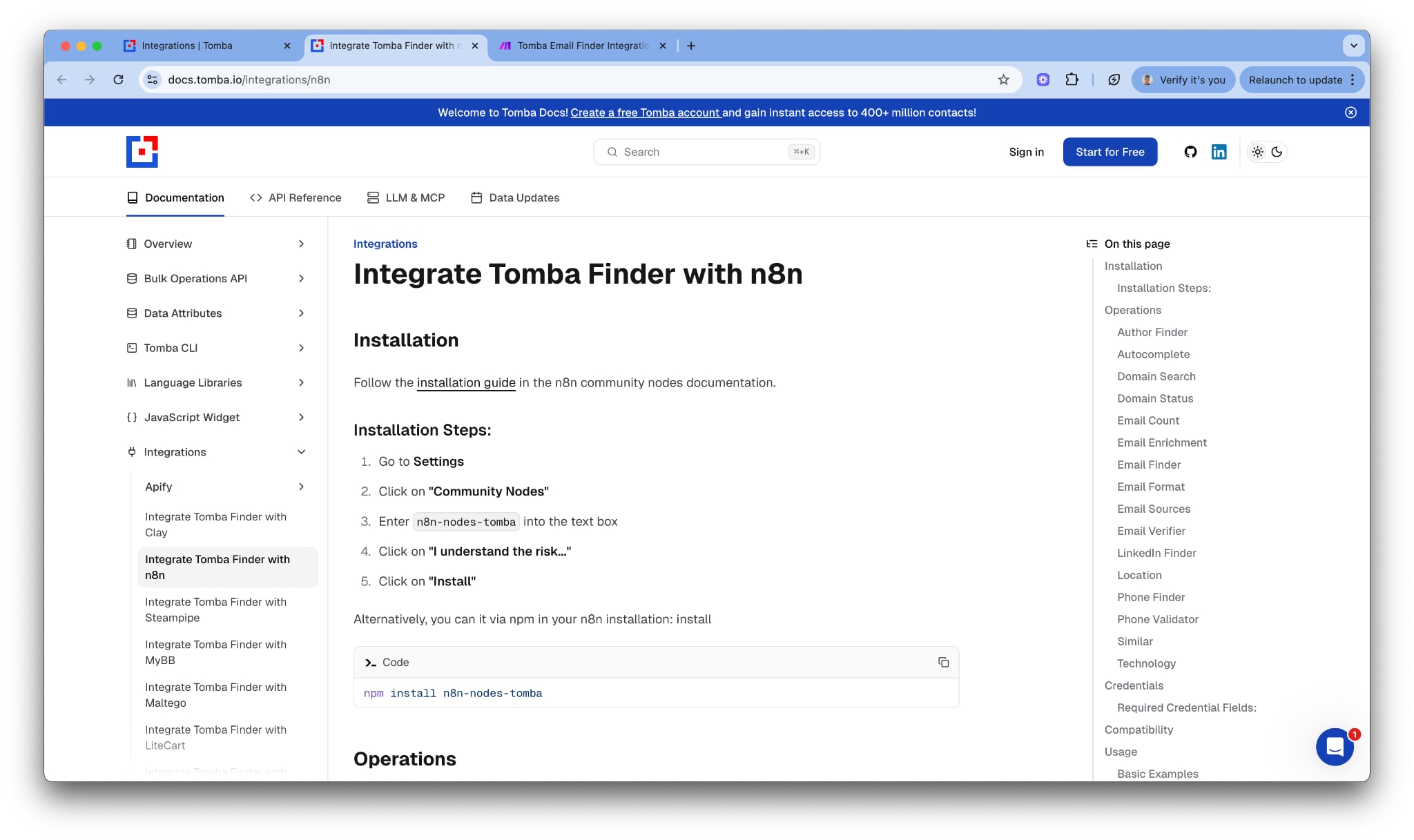
LinkedIn API & App
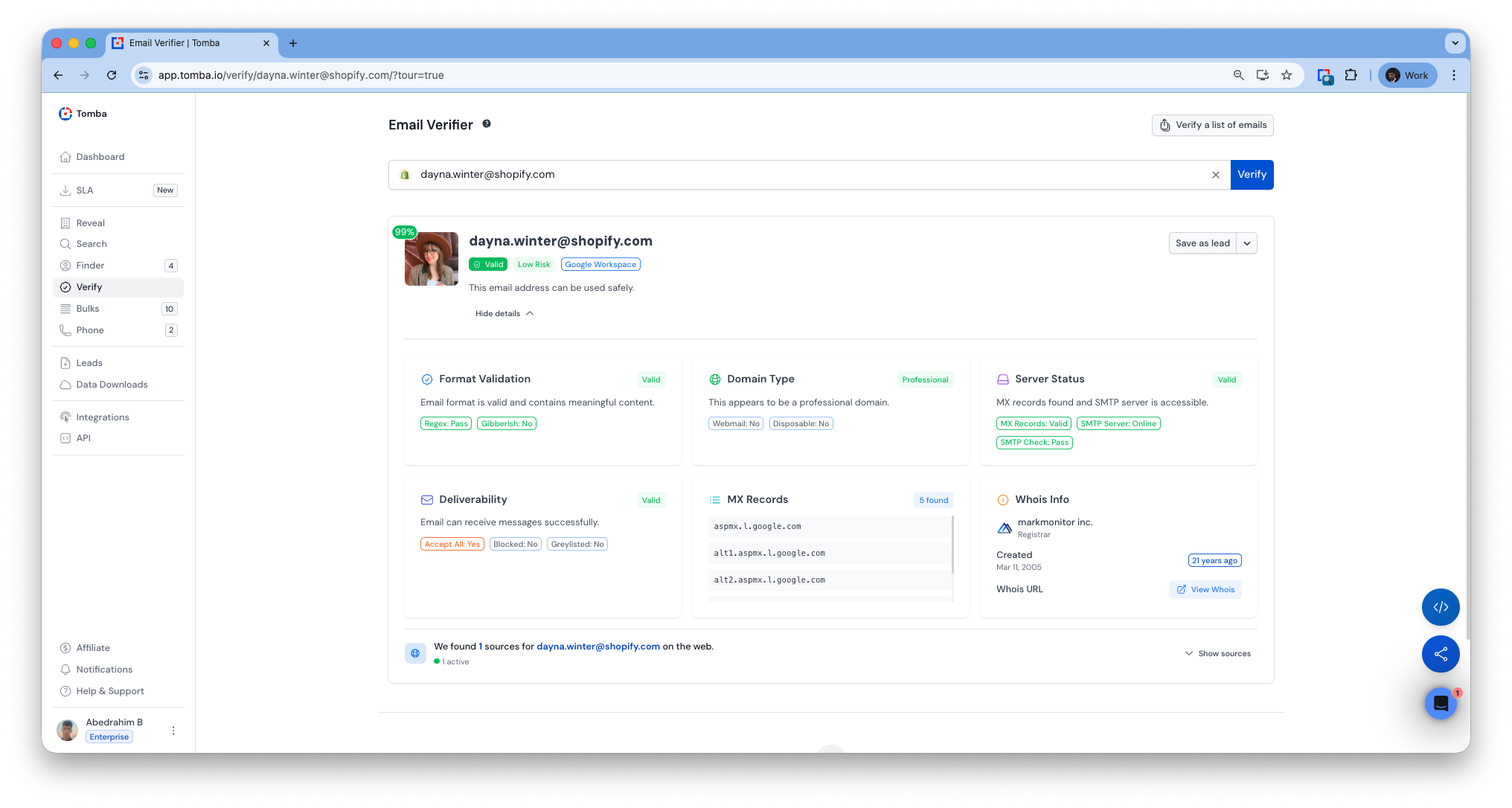
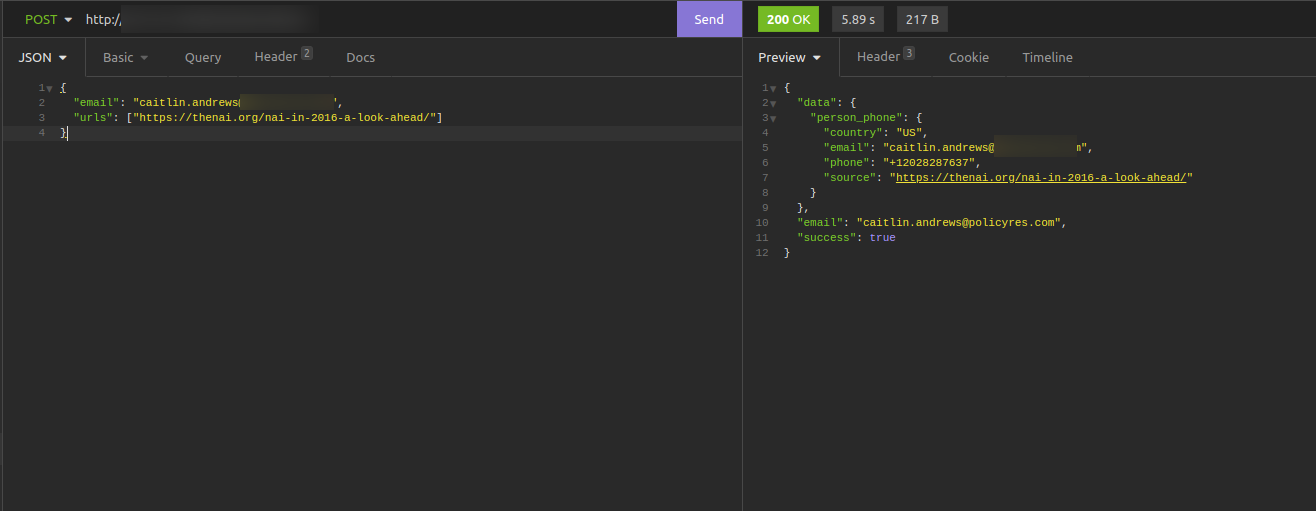
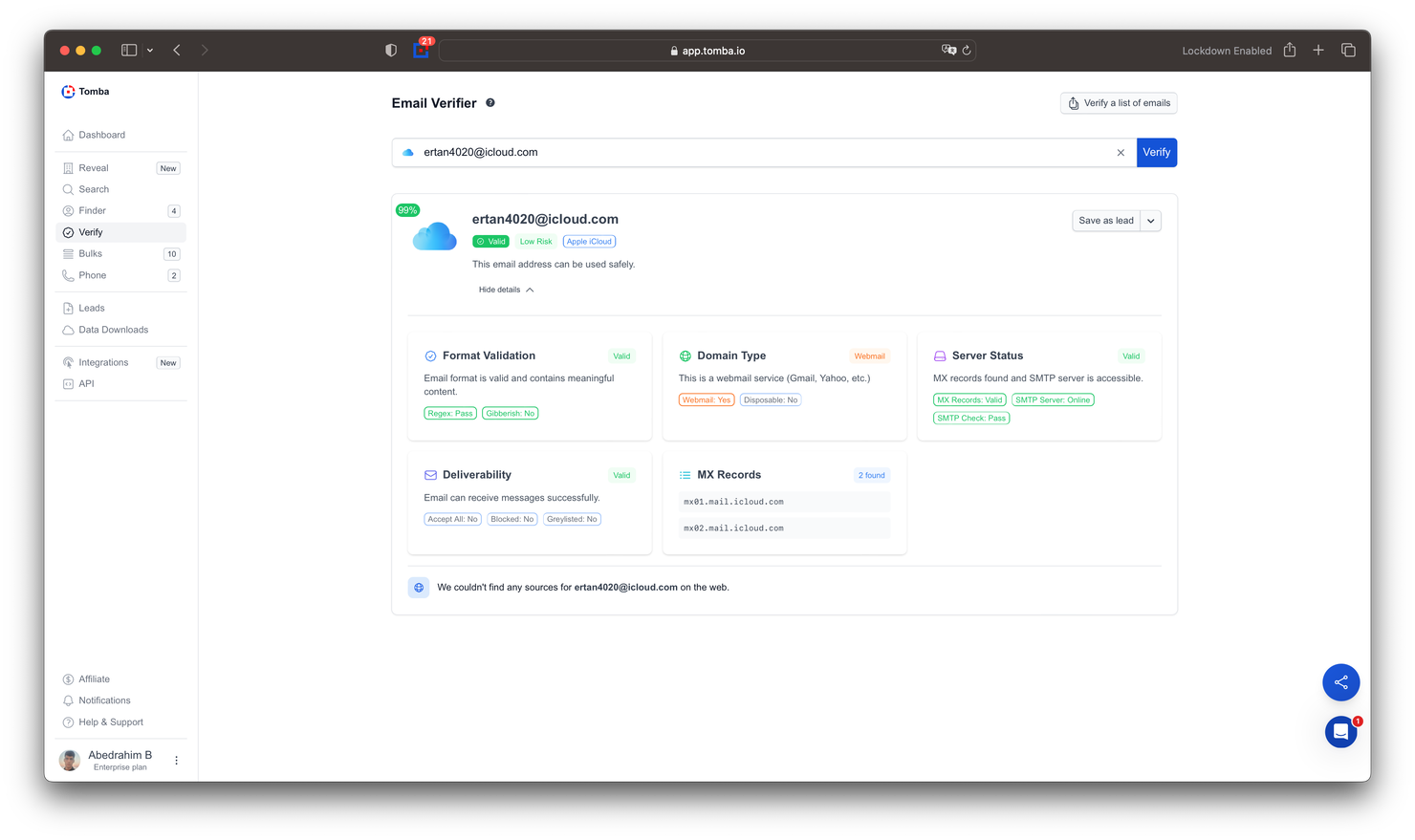
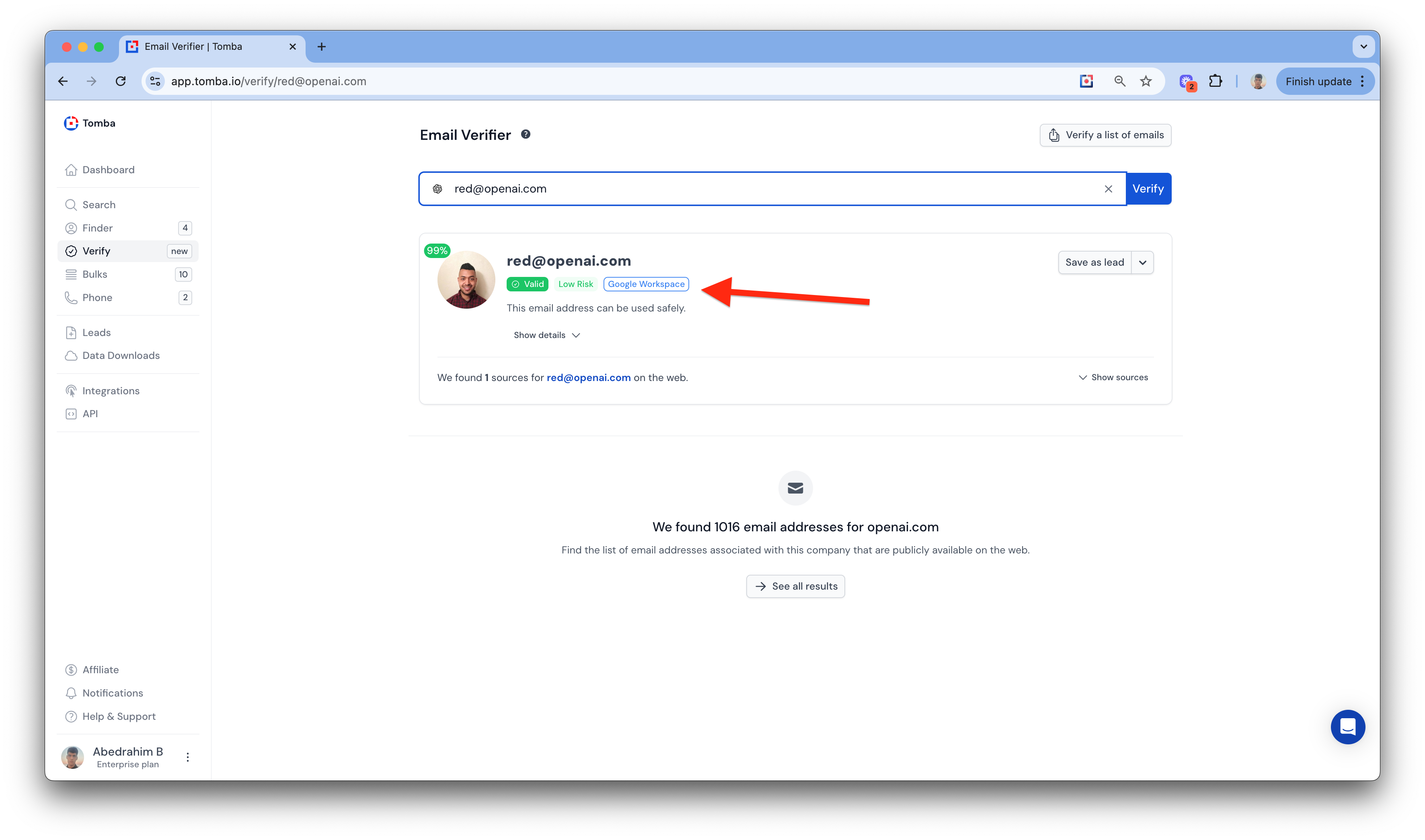
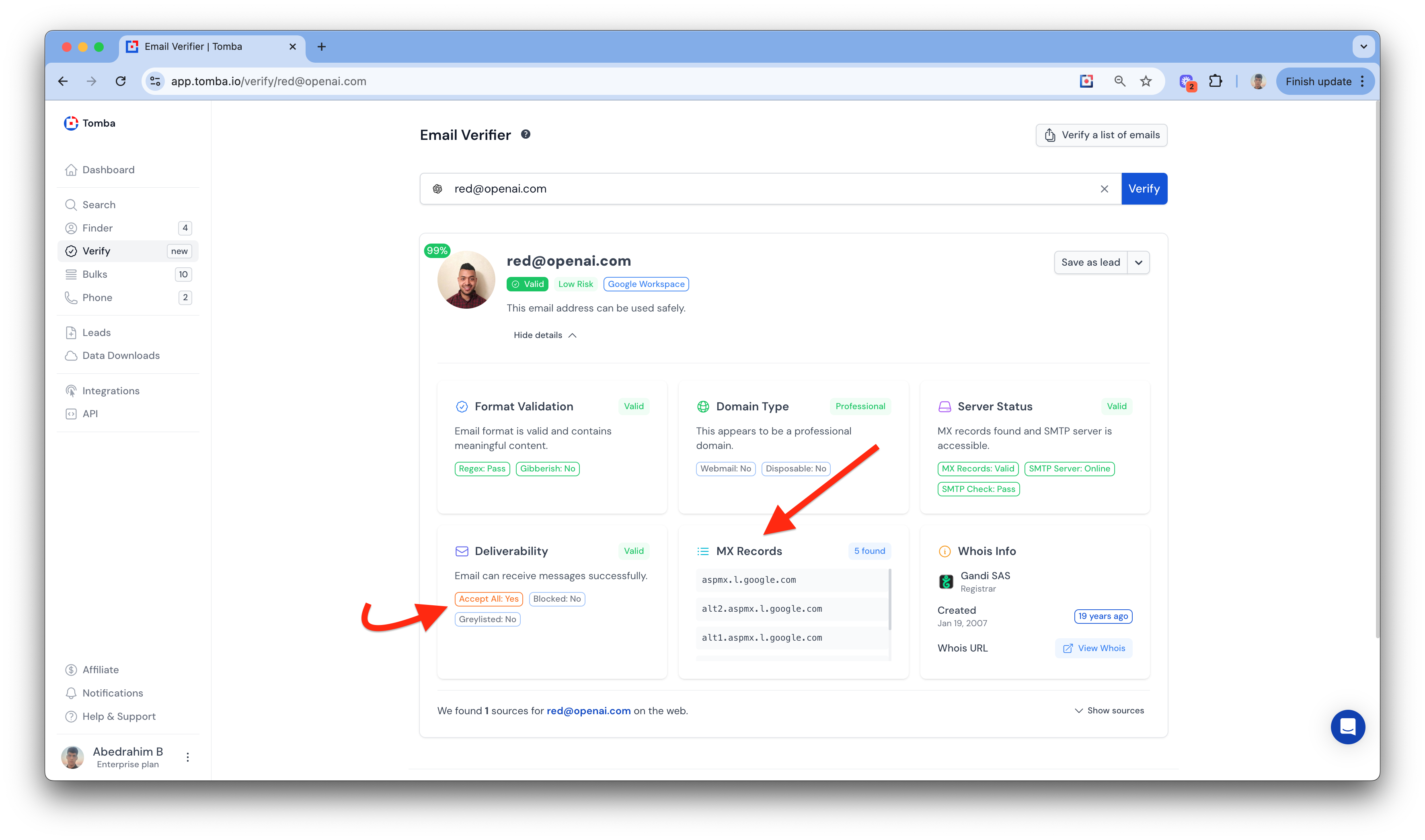
Shows only valid emails by checking multiple addresses and returning the verified one.
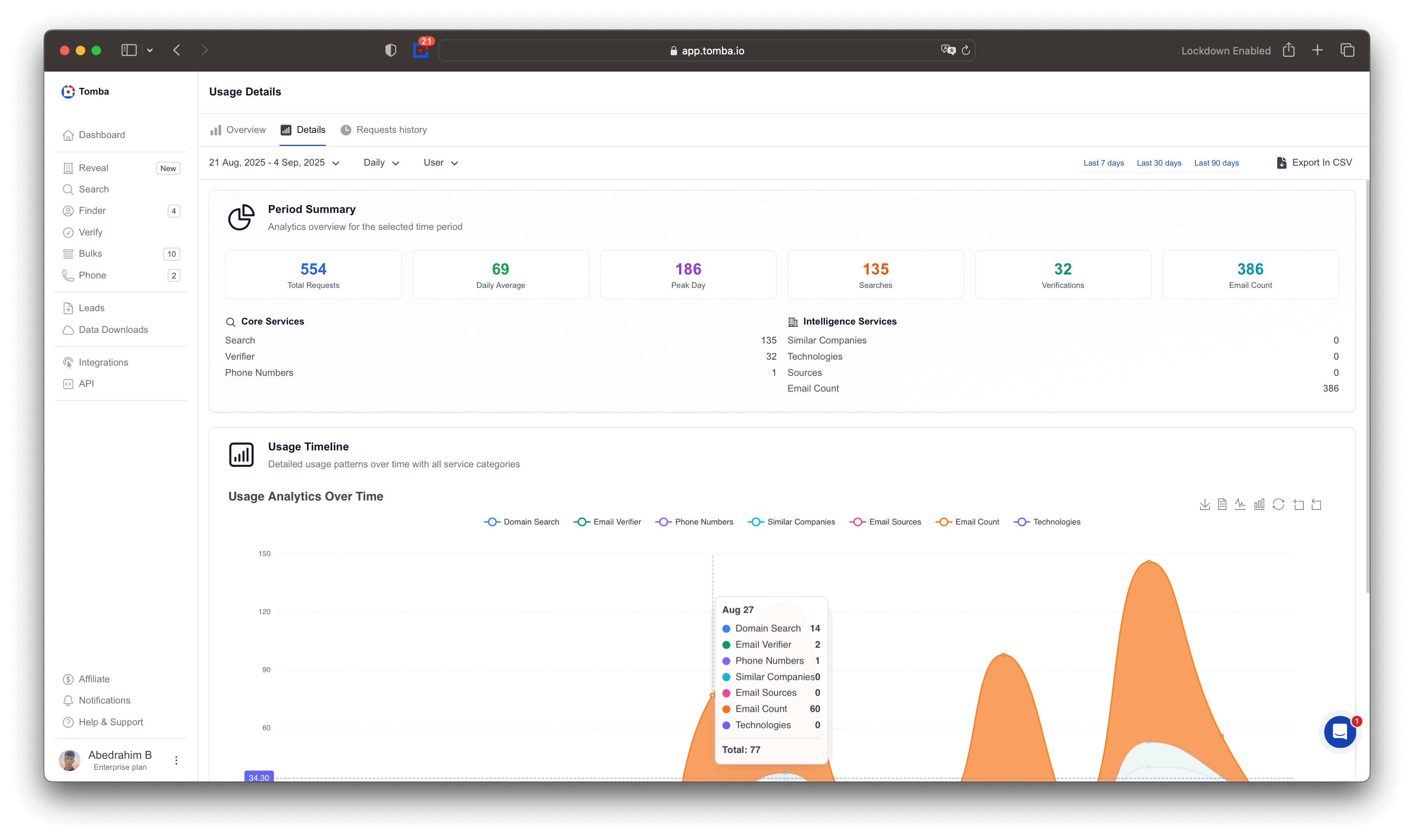
Smarter Email Validation
We’ve updated the email verification again, and it’s better than ever.
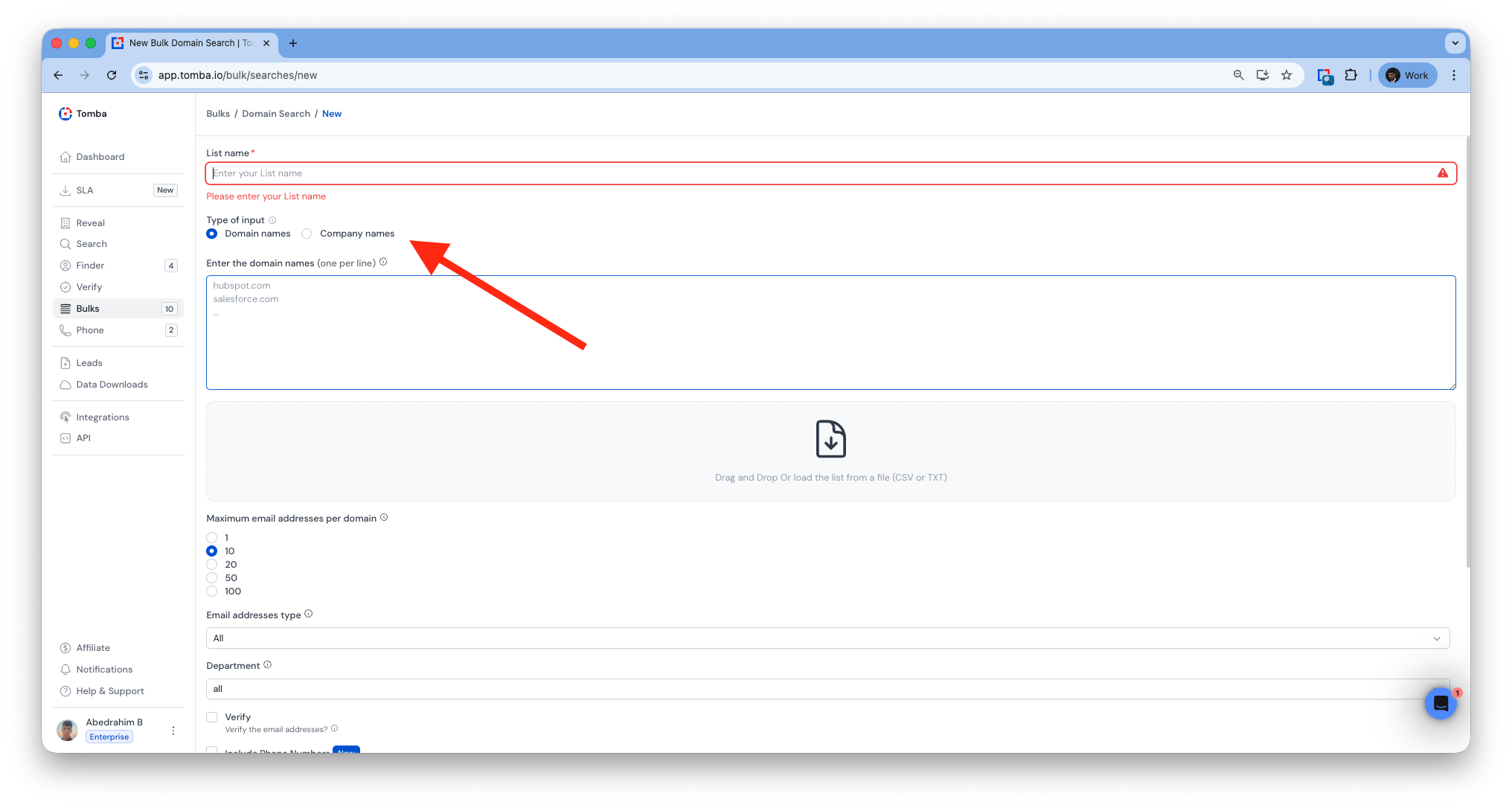
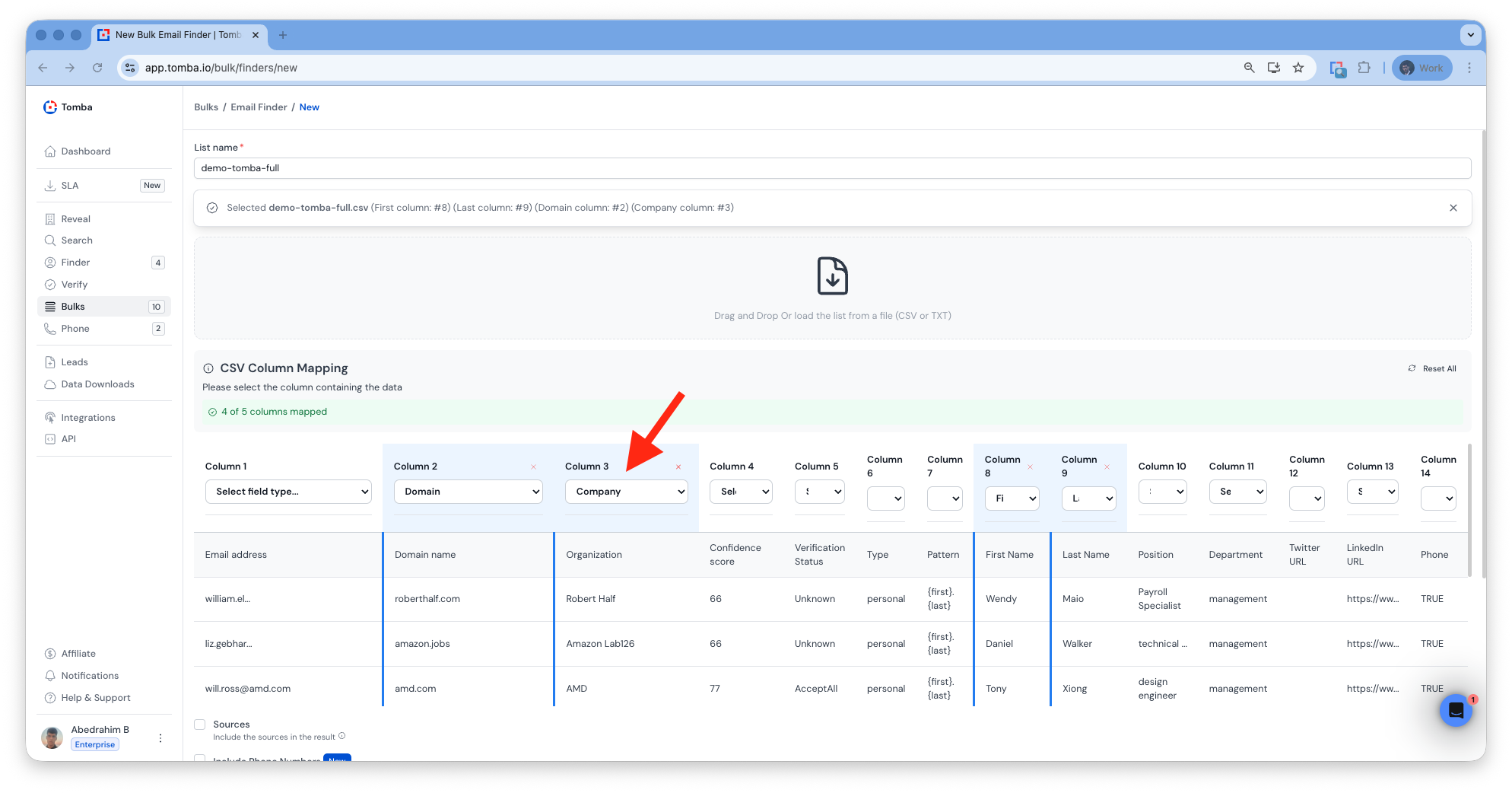
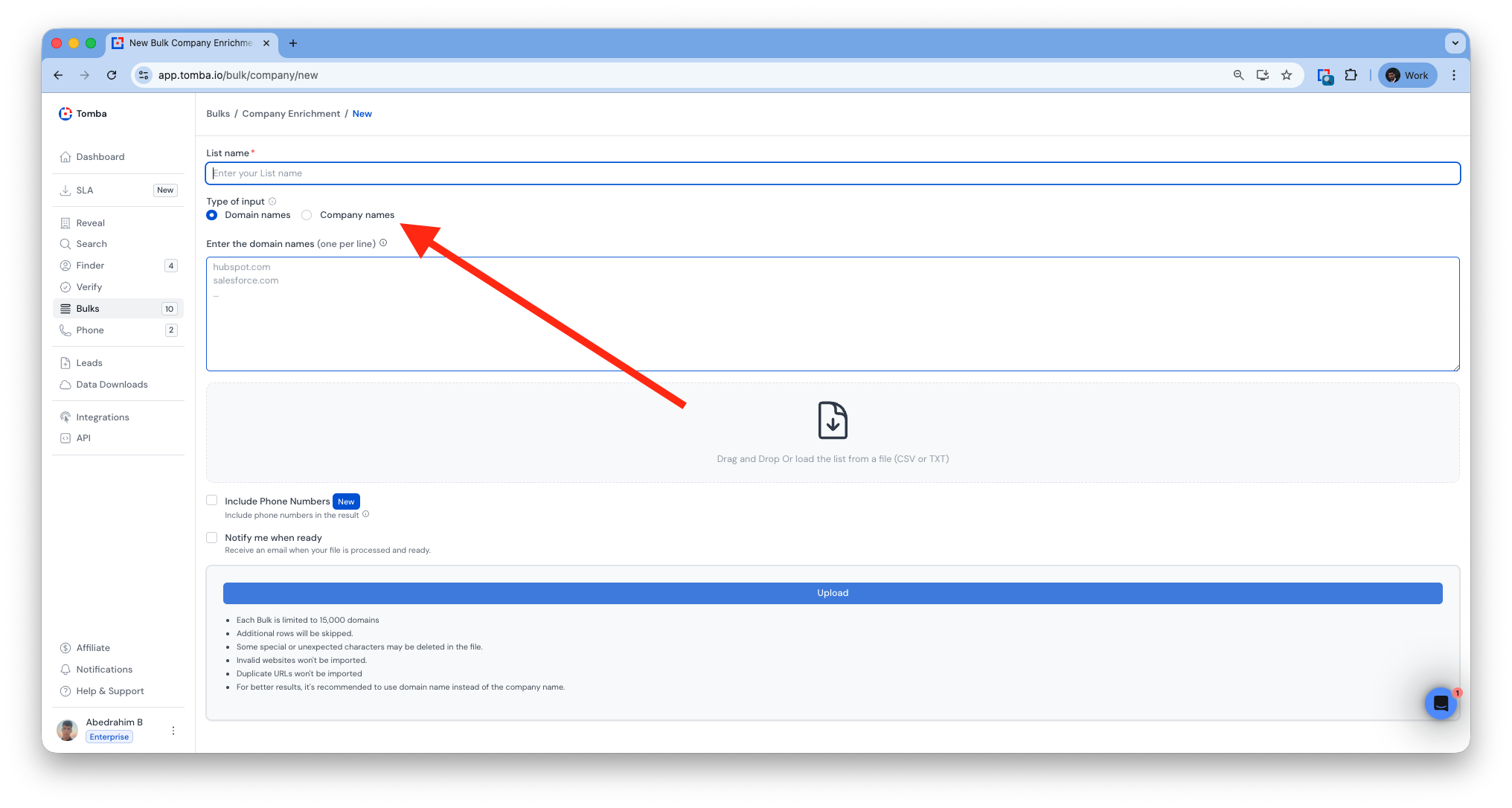
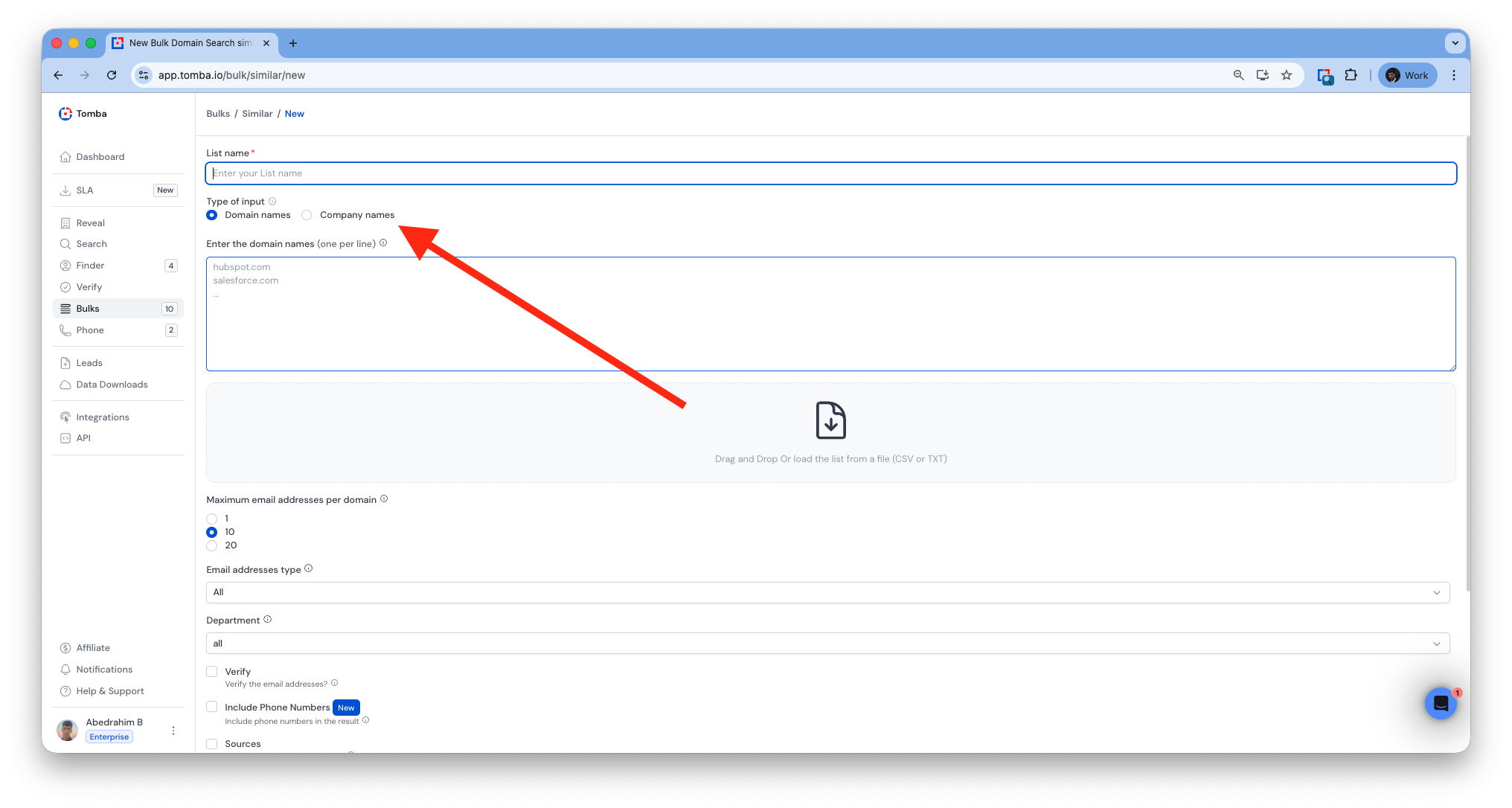
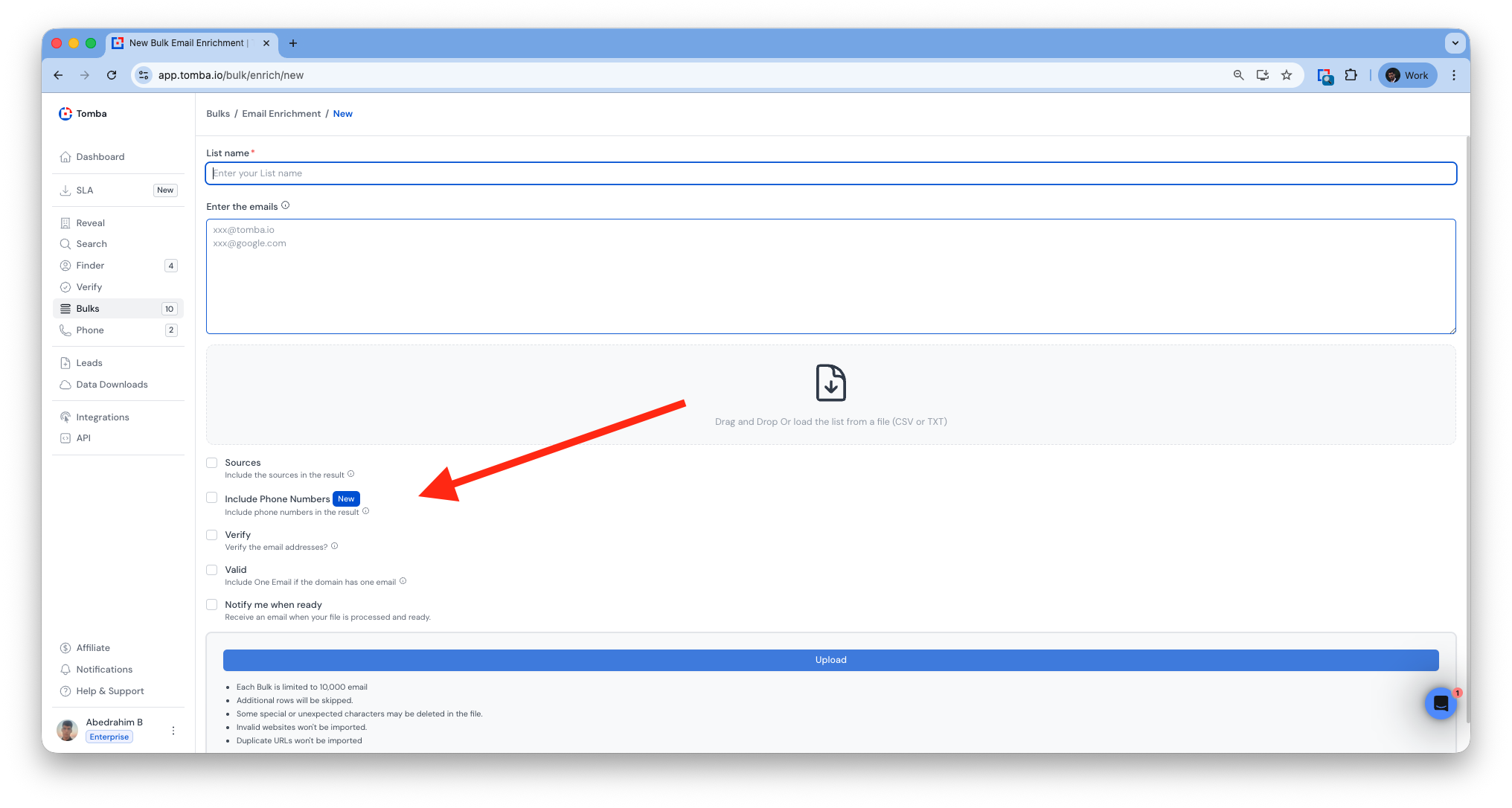
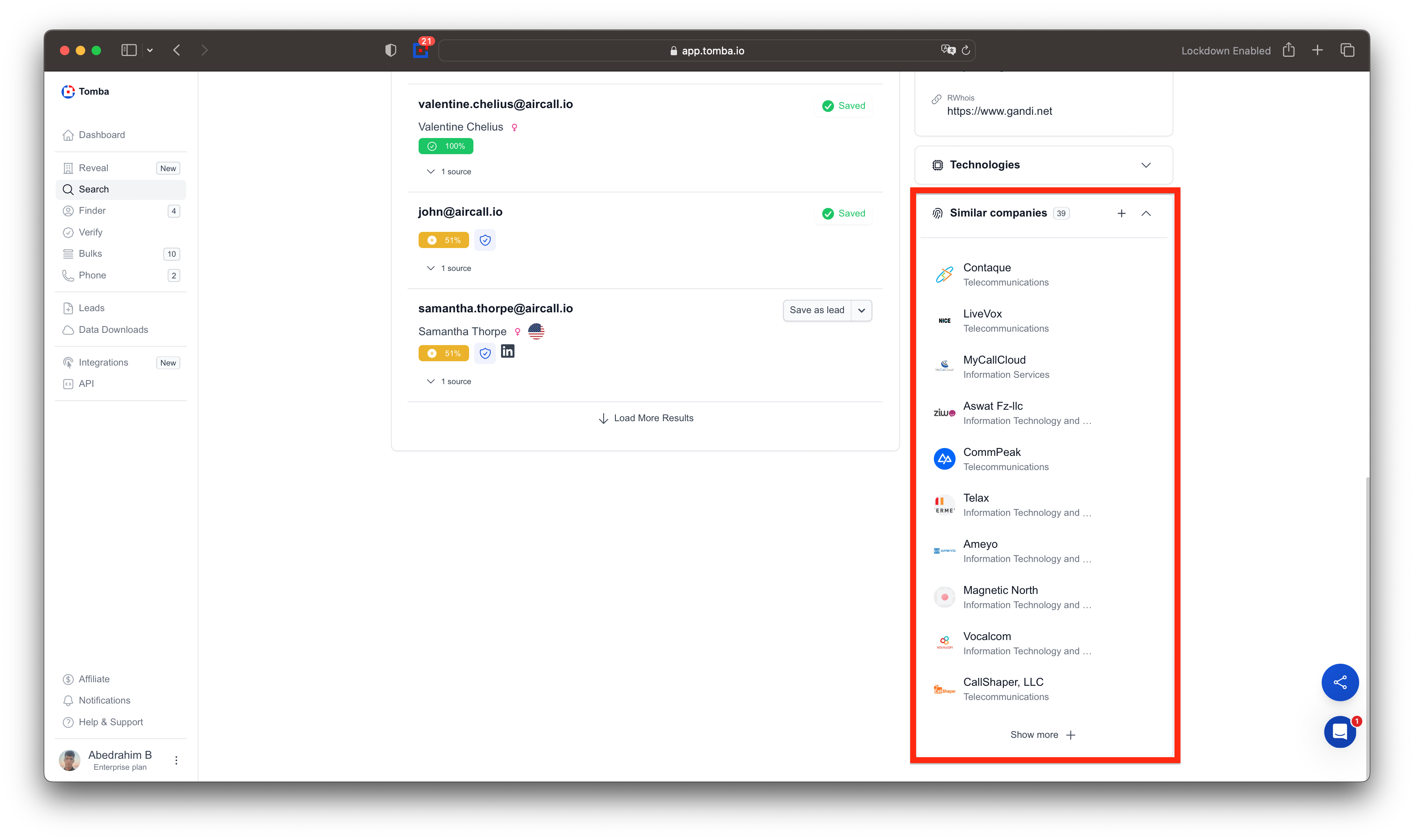
Company Name Support (Bulk)
Added support for company name detection across all bulk tools.
Better matching between domains, emails, and company data.
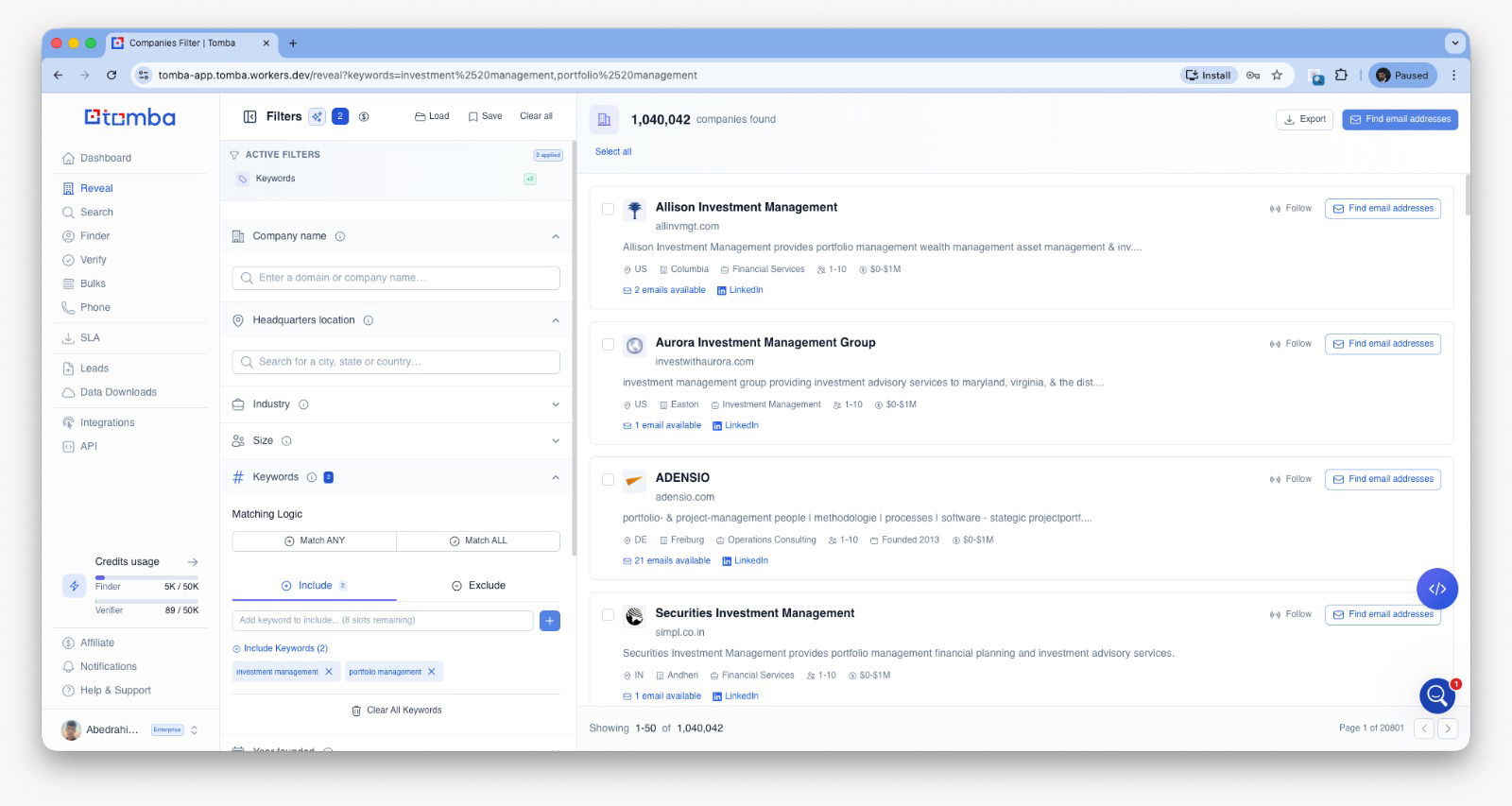
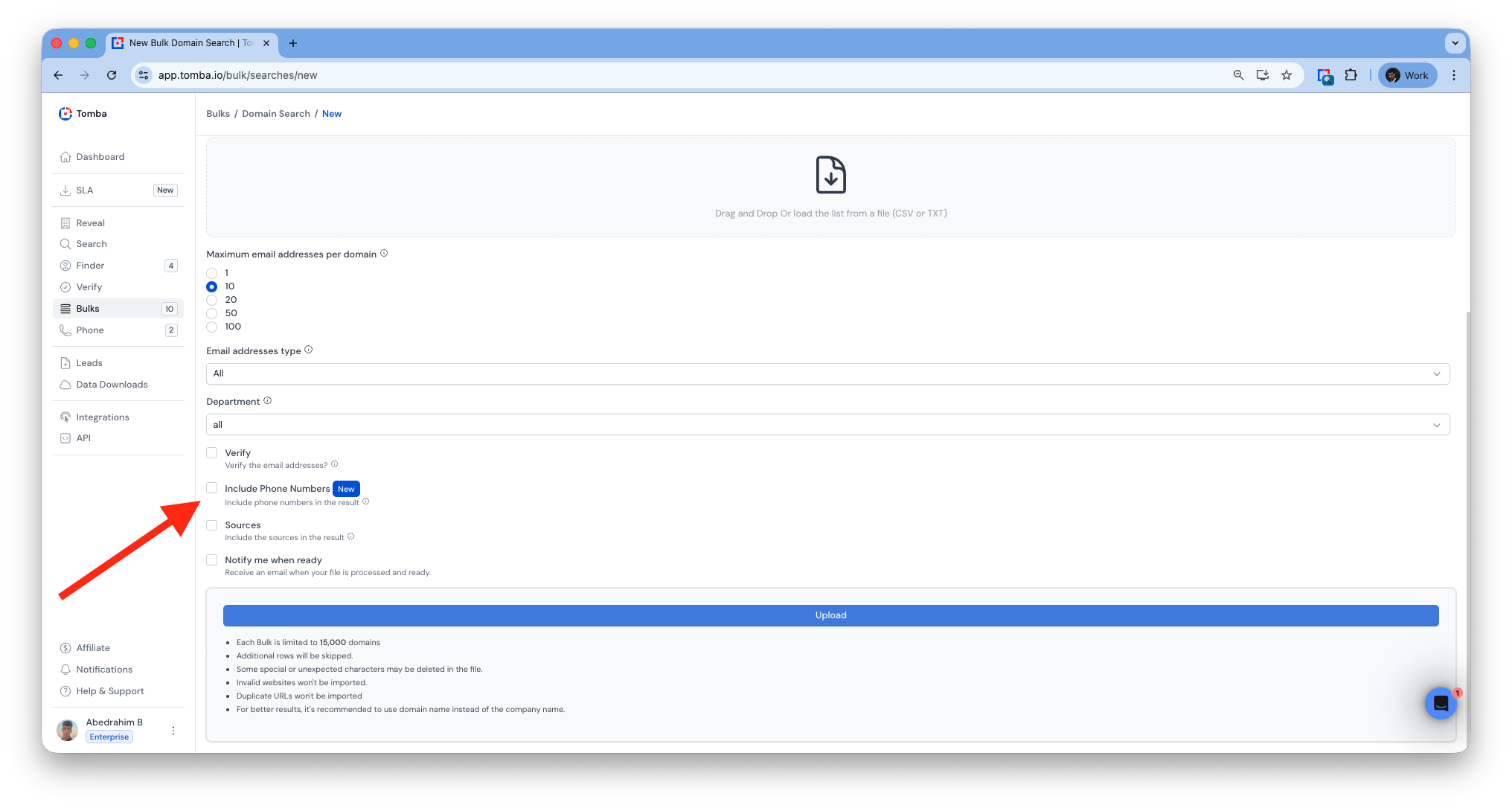
Bulk Domain Search
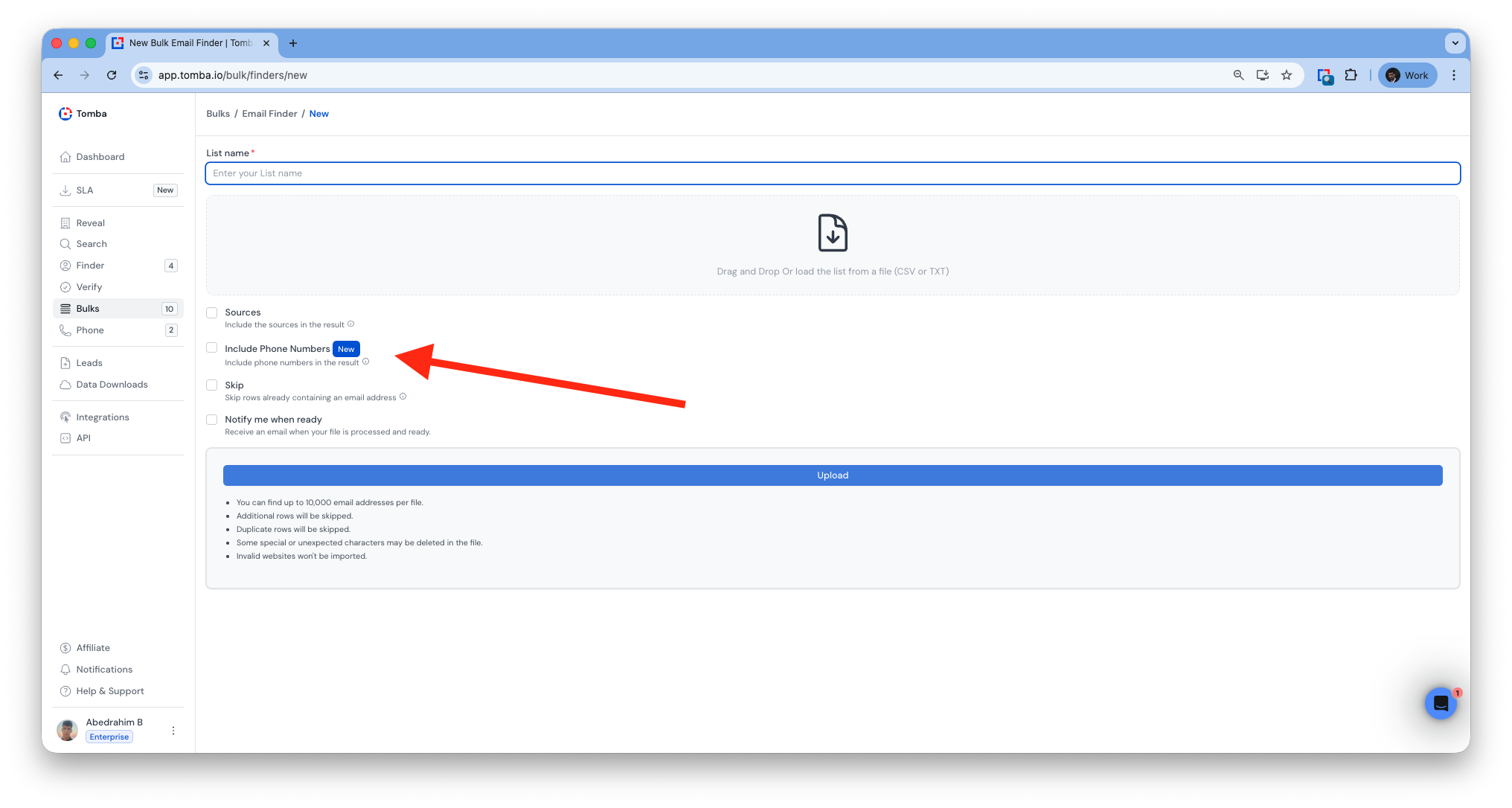
Bulk Email Finder
Bulk company Enrichment
Bulk Similar Domains
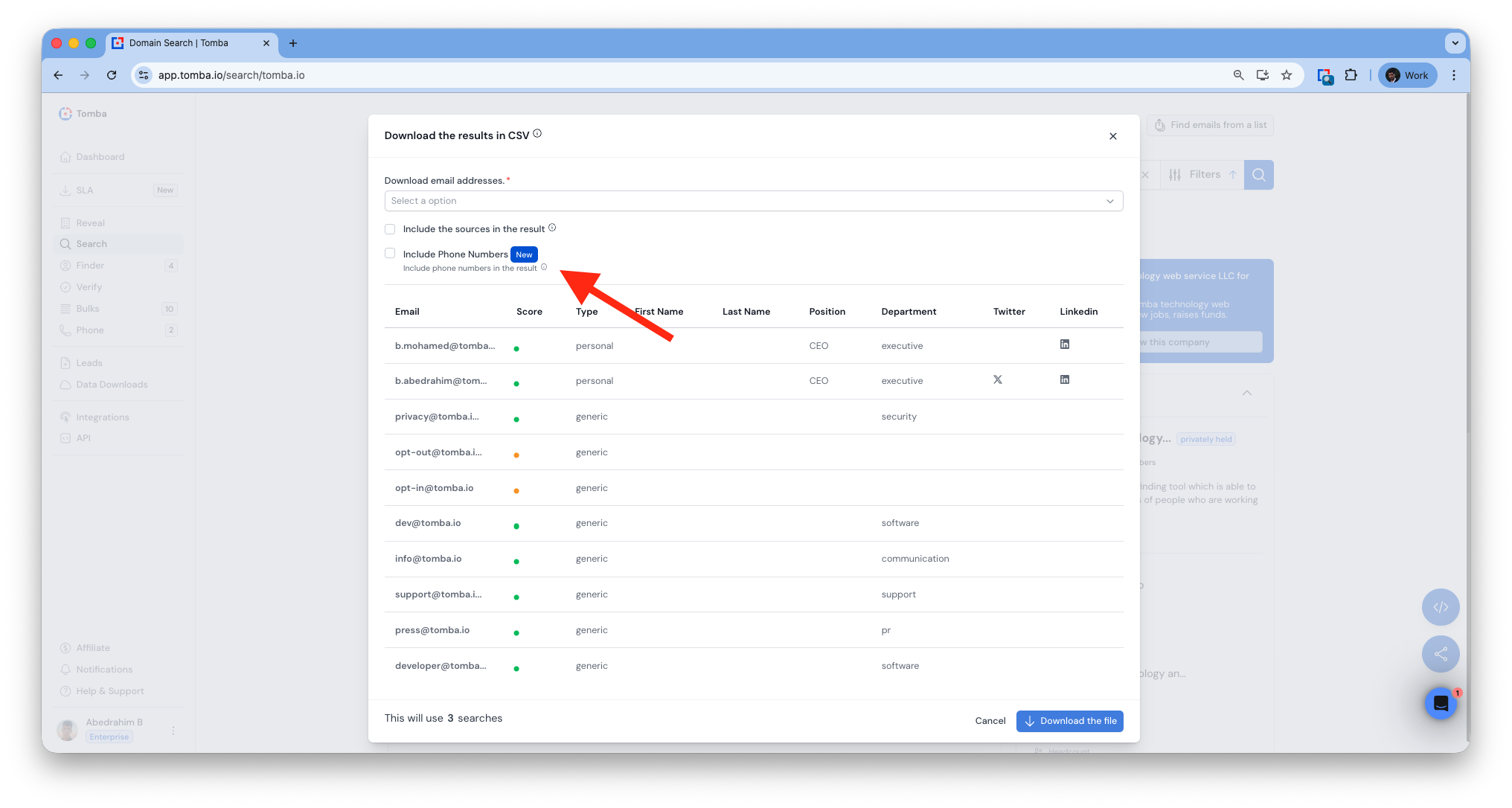
Mobile Number Enrichment
Added mobile enrichment to all bulk tools.
Mobile numbers now included in exports where available.
Mobile number support in all API endpoint
API Improvements
Increased rate limits across all API endpoints.
Faster responses and better stability for high-volume usage.
Node Package & MCP Updates
Updated Node package with latest improvements.
Updated local MCP for better performance and compatibility.
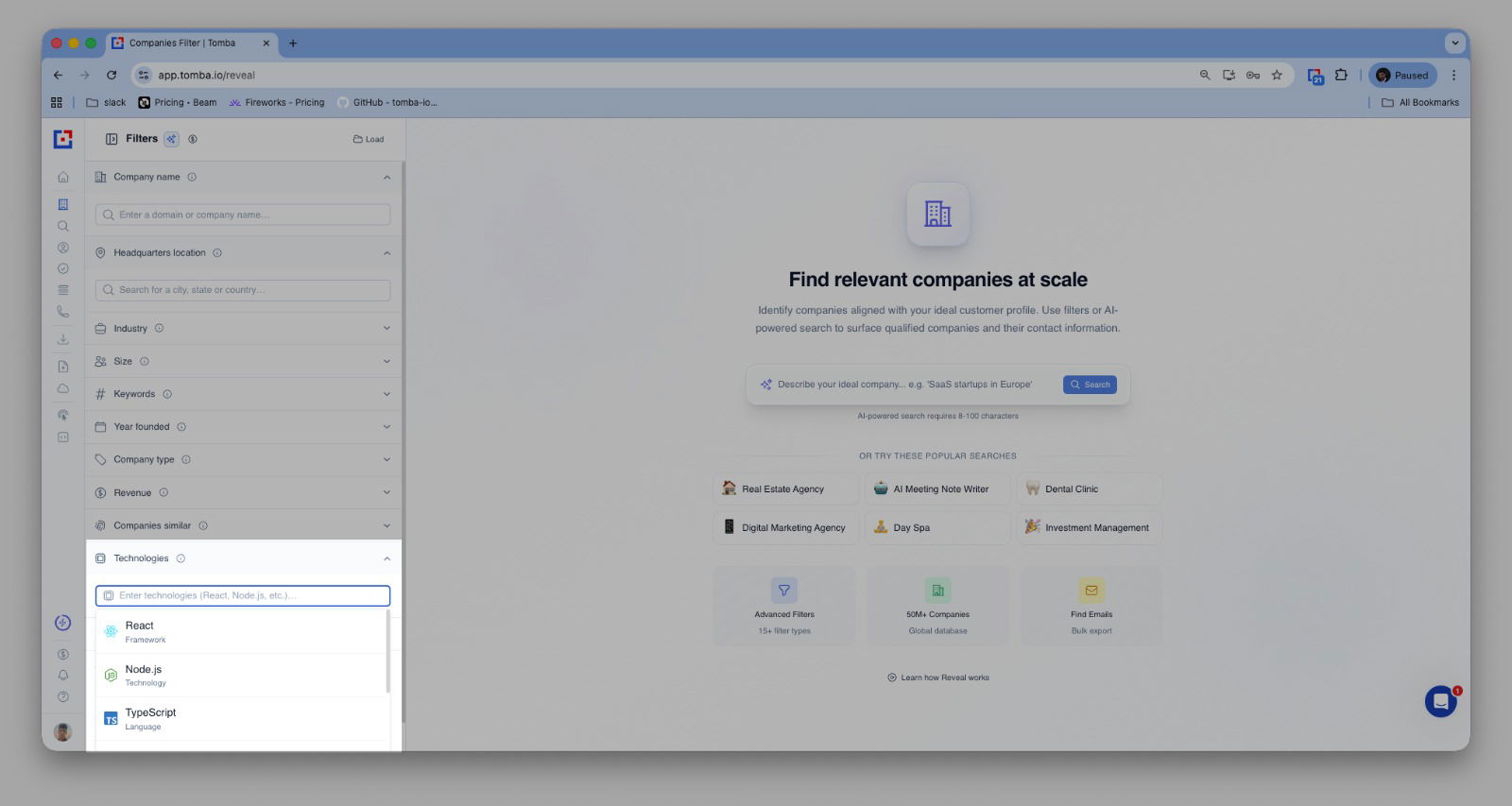
Chrome Extension Updates
Fixed known bugs and improved stability.
Updated Chrome extension for a smoother user experience.
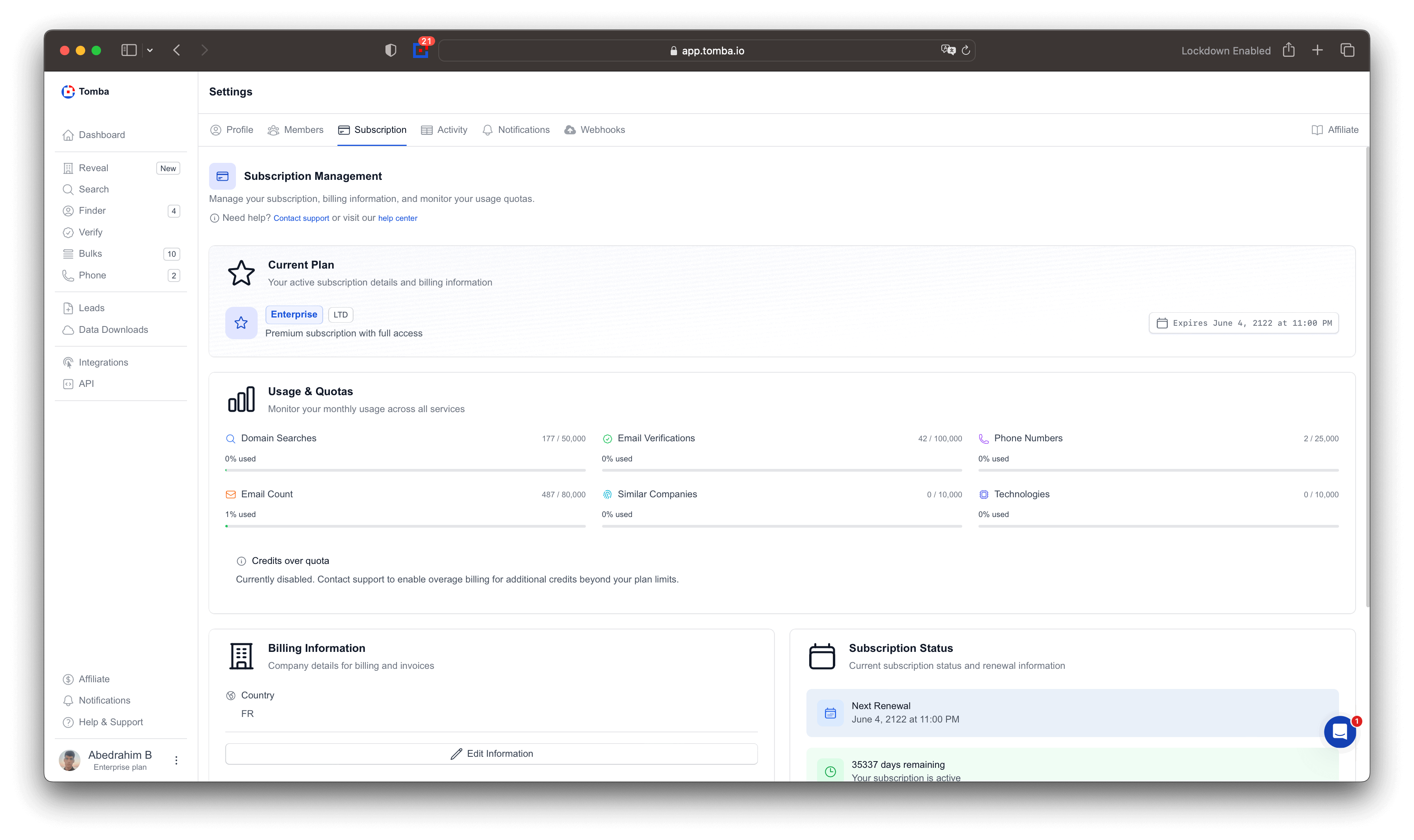
Bulk Export Limit Increase
Daily bulk export limit increased from 15 to 30.
More flexibility for power users.
Performance & Reliability
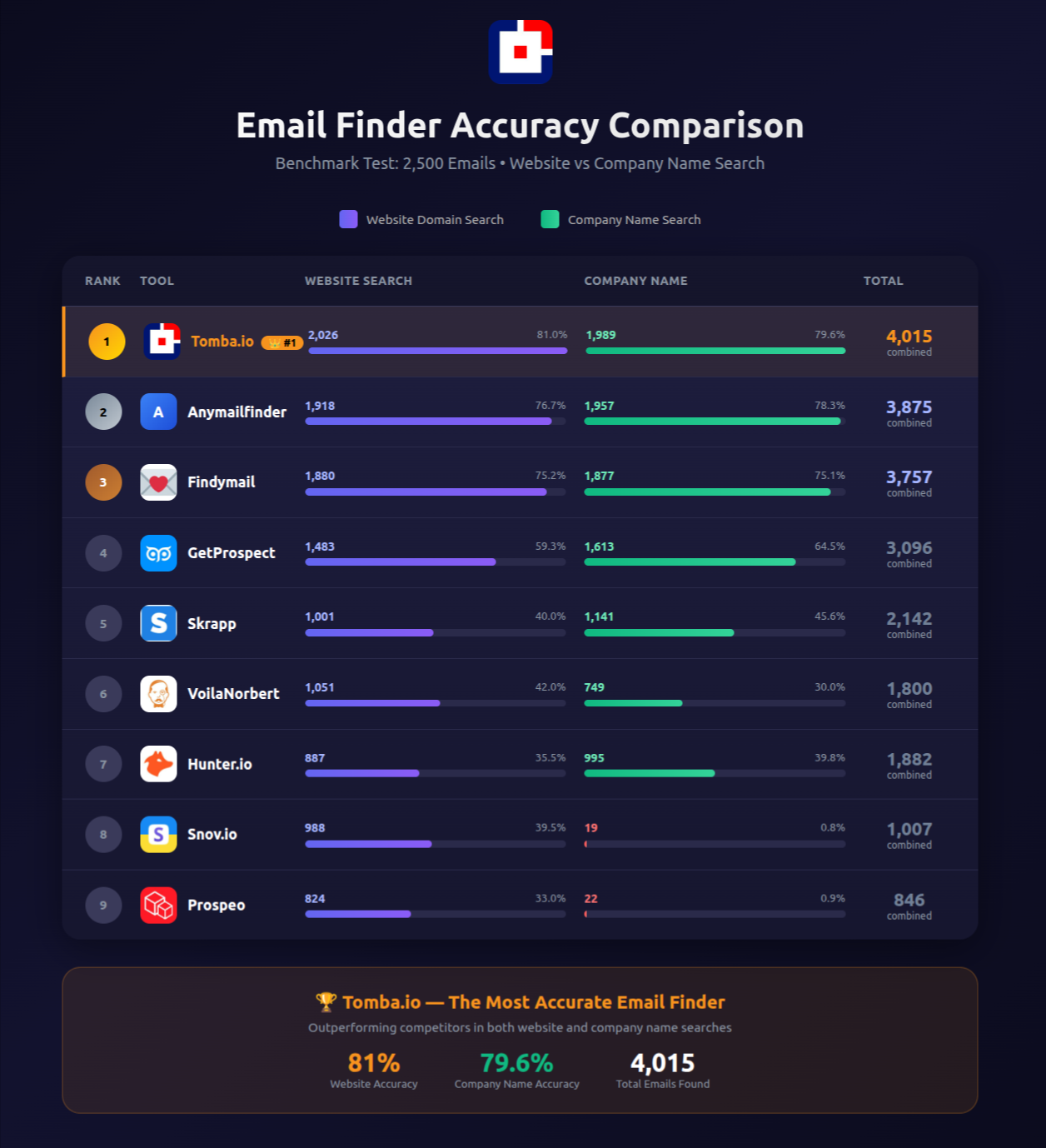
We continue to be #1 in email finding and domain search worldwide.
Overall performance, accuracy, and system stability improved.
Internal stats confirm higher success rates across all tools.
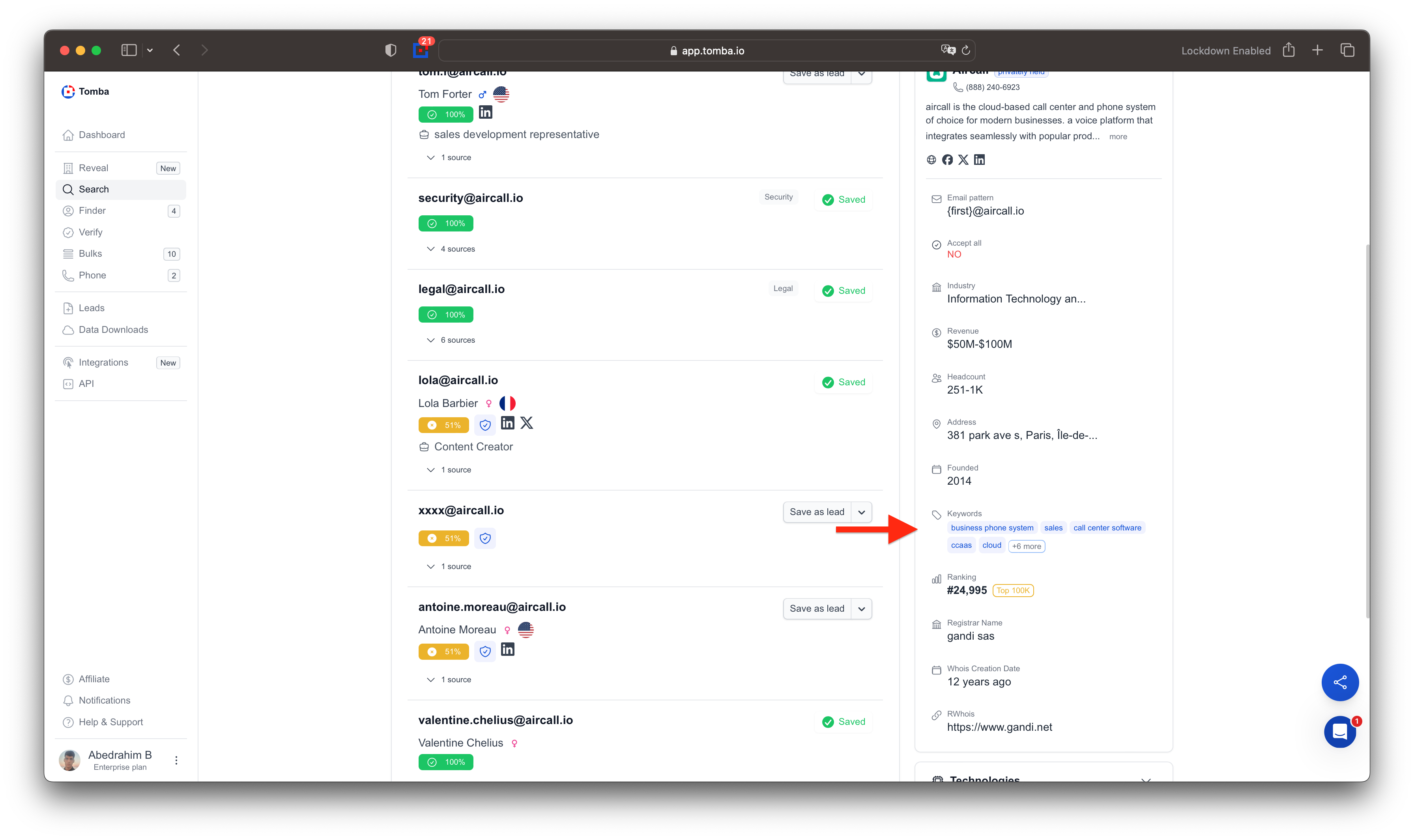
Crawler Update
Updated crawler to detect more phone numbers and more emails
This update includes February data import
February 2026 Data Update
We processed hundreds of millions of records to maintain fresh, accurate, and complete datasets.
Here's what changed this month:
Data Updates
Total Records Processed: 735M pages crawled
Unique B2B Emails: 49.49M high-quality business emails
Data Quality: 99.91% valid email rate with minimal duplication
Collection Period: 10 days of continuous web crawling
Overview Statistics
Total Crawled Pages: 735.56M
Unique B2B Emails: 49.49M
Duplication Rate: 93.27%
Invalid Email Rate: 0.09%
Data Collection Period: 10 Days
Pages Processed: 735 Million Pages in 10 days
Overview statistics
Top 10 Domains
inbox.sourceware.org: 777.59K records
hsw.com.pl: 508.96K records
bgu.ru: 468.69K records
wtcgdynia.com.pl: 467.90K records
nagasawa-mfg.co.jp: 465.34K records
public-inbox.org: 458.74K records
jsimlo.sk: 401.68K records
marocannuaire.org: 376.10K records
tvwatchers.nl: 369.57K records
macrumors.com: 349.12K records
Top 10 domains
Role-Based Email Types
info@: 182.36M emails
contact@: 18.01M emails
sales@: 16.09M emails
support@: 14.32M emails
office@: 7.99M emails
hello@: 7.86M emails
kontakt@: 4.53M emails
mail@: 4.18M emails
service@: 3.96M emails
contato@: 2.92M emails
Total Role-Based: 336.36M (45.8% of all emails)
Role-based email types
Top 15 Countries
Generic TLD: 334.00M records
Russia: 49.35M records
Germany: 45.94M records
Poland: 26.50M records
Italy: 23.65M records
United Kingdom: 17.39M records
Czech Republic: 15.82M records
Netherlands: 14.09M records
France: 12.22M records
Brazil: 11.20M records
Spain: 8.04M records
Sweden: 7.83M records
Switzerland: 7.75M records
Australia: 7.70M records
Canada: 7.14M records
Top 15 countries
Domain Categories
Other: 464.83M records
E-commerce: 81.64M records
News: 40.69M records
Blog: 40.02M records
Education: 27.47M records
Technology: 20.83M records
Business: 16.89M records
Entertainment: 14.95M records
Government: 14.13M records
Social: 11.89M records
Adult: 2.21M records
Domain categories
Email Analysis
Webmail Domains: 116.90M (236.2% of unique B2B Emails)
Business Domains: 617.98M (84.1% of total)
Role-Based Emails: 336.36M (45.8% of all emails)
File Extension Junk: 681.25K detected and filtered
Valid Email Rate: 99.91%
Role-based emails include: info@, sales@, support@, contact@, office@, hello@, kontakt@, mail@, service@, and more.
Email analysis
Daily Time Series (Last 10 Days)
2026-01-16: 58.38M records
2026-01-17: 58.85M records
2026-01-18: 58.69M records
2026-01-19: 55.54M records
2026-01-20: 56.13M records
2026-01-21: 58.30M records
2026-01-22: 58.24M records
2026-01-23: 55.58M records
2026-01-24: 54.02M records
2026-01-25: 32.62M records
Peak day: January 17, 2026 with 58.85M records processed.
Daily time series
Key Highlights
Record Quality: Achieved 99.91% valid email rate
Deduplication Efficiency: 93.27% duplication rate shows effective filtering
Role-Based Coverage: 336.36M role-based emails identified across all industries
Geographic Reach: Coverage spans 30+ countries with strong presence in Europe and Asia
Category Diversity: E-commerce leads with 81.64M records, followed by News and Blog sectors
Growth: 14.8% increase in total records processed compared to January 2026